Many work processes would be almost unthinkable today without robots. But robots operating in manufacturing facilities have often posed risks to workers because they are not responsive enough to their surroundings.
To make it easier for people and robots to work in close proximity in the future, Prof. Matthias Althoff of the Technical University of Munich (TUM) has developed a new system called (IMPROV) that uses interconnectable modules for self-programming and self-verification.
When companies use robots to produce goods, they generally have to position their automatic helpers in safety cages to reduce the risk of injury to people working nearby. A new system could soon free the robots from their cages and thus transform standard practices in the world of automation.
Althoff has developed a toolbox principle for the simple assembly of safe robots using various components. The modules can be combined in almost any way desired, enabling companies to customize their robots for a wide range of tasks – or simply replace damaged components. Althoff’s system was presented in a paper in the June 2019 issue of Science Robotics.
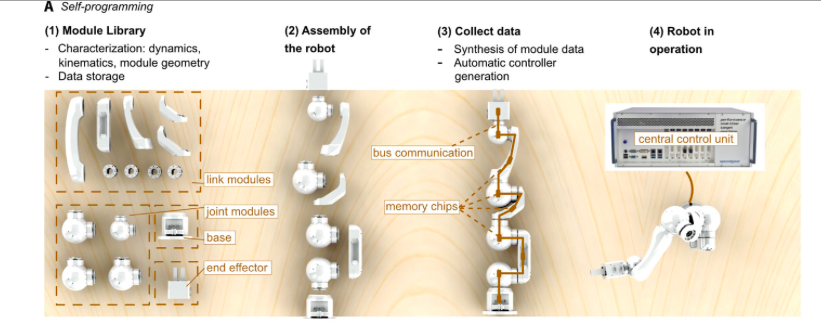
Built-in chip enables the robot to program itself
Robots that can be configured individually using a set of components have been seen before. However, each new model required expert programming before going into operation. Althoff has equipped each module in his IMPROV robot toolbox with a chip that enables every modular robot to program itself on the basis of its own individual toolkit.
In the Science Robotics paper, the researchers said “self-programming of high-level tasks was not considered in this work. The created models were used for automatically synthesizing model-based controllers, as well as for the following two aspects.”
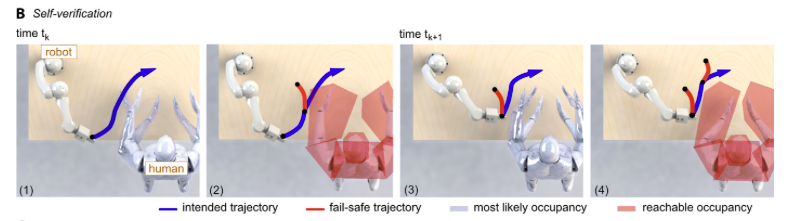
Self-verification
To account for dynamically changing environments, the robot formally verified, by itself, whether any human could be harmed through its planned actions during its operation. A planned motion was verified as safe if none of the possible future movements of surrounding humans leads to a collision.
Because uncountable possible future motions of surrounding humans exist, Althoff bound the set of possible motions using reachability analysis. Althoff said the inherently safe approach renders robot cages unnecessary in many applications.

Scientist Christina Miller working on the modular robot arm. Credit: A. Heddergott/TUM
Keeping an eye on the people working nearby
“Our modular design will soon make it more cost-effective to build working robots. But the toolbox principle offers an even bigger advantage: With IMPROV, we can develop safe robots that react to and avoid contact with people in their surroundings,” said Althoff.
With the chip installed in each module and the self-programming functionality, the robot is automatically aware of all data on the forces acting within it as well as its own geometry. That enables the robot to predict its own path of movement.
At the same time, the robot’s control center uses input from cameras installed in the room to collect data on the movements of people working nearby. Using this information, a robot programmed with IMPROV can model the potential next moves of all of the nearby workers. As a result, it can stop before coming into contact with a hand, for example – or with other approaching objects.
“With IMPROV we can guarantee that the controls will function correctly. Because the robots are automatically programmed for all possible movements nearby, no human will be able to instruct them to do anything wrong,” says Althoff.
IMPROV shortens cycle times
For their toolbox set, the scientists used standard industrial modules for some parts, complemented by the necessary chips and new components from the 3D printer. In a user study, Althoff and his team showed that IMPROV not only makes working robots cheaper and safer – it also speeds them up: They take 36% less time to complete their tasks than previous solutions that require a permanent safety zone around a robot.
Editor’s Note: This article was republished from the Technical University of Munich.
 Keynotes
Keynotes